Шафранюк
Артём Сергеевич
Универсальное
вычислительное обучение
Киев,
Украина 1999
Рецензия
План
- Введение
- Цель
работы
- Решение
- Выводы
- Литература
I.
Введение
1.
Информация и её обработка
Проблема
искусственного интеллекта долгое
время оставалась нерешённой и в
принципе остаётся таковой до сих
пор. Компьютерные программы
наглядно доказали свою силу пока
только в решении прикладных
проблем, являющихся почти
исключительно частными случаями.
Например, алгоритм alpha-beta minimax search,
использованный шахматным
компьютером Deep Blue, победившим
мирового чемпиона, является
ориентированным исключительно на
игру в шахматы, и его область
применения ограниченна игрой в
шахматы или каким-либо подобным
процессом обработки информации.
Текстовый редактор Microsoft Word 97, в
котором набирается этот текст,
исправно расставляет запятые и
находит даже грамматические
ошибки, но трудно представить,
чтобы подпрограмма, расставляющая
запятые, была способна на что-либо
совсем другое.
Со времён ещё до
нашей эры человечество искало
ответы на вопросы о природе и цели
разума. Какова в точности цель
науки? Каковы обобщённые методы
изучения реального мира? Как
формируются гипотезы? По каким
причинам следует предпочесть одну
гипотезу другим? Подобные вопросы
обсуждаются до сих пор. Самым
интересным является то, что за
последние 35 лет удивительные
фундаментальные открытия в области
компьютерной науки позволили
взглянуть на эти вопросы
совершенно по-новому.
Традиционные
науки о природе изучают её
непосредственным путём, но
существует несколько иной подход,
связанный с тем, что всё без
исключения является информацией,
подчиняется общим законам,
присущим ей и изучаемым науками об
информации, как правило, тесно
связанными с использованием
компьютеров. Это хорошо
иллюстрируется тем, что все
современные теоретические
исследования в области физики и
большинства других наук сейчас
невозможны без применения
компьютеров, позволяющих, кроме
выполнения расчётов, ещё и
симулировать реальные процессы.
Наилучшим примером этого является
моделирование ядерных взрывов,
которое часто позволяет ведущим
странам мира отказаться от
физических испытаний ядерного
оружия. Наглядным и доступным
примером являются трёхмерные
компьютерные игры, которые с каждым
годом становятся всё реалистичнее.
Мир,
воспринимаемый человеком, - лишь
незначительная дискретная часть
реальности, проектируемая на мозг
через органы чувств в качестве
информации. Например, свет, видимый
нами, электромагнитное излучение в
диапазоне 0,4..0,75 микрон – всего лишь
узкая полоска в полном
электромагнитном спектре. Слышимый
звук в диапазоне 20Hz…20kHz также
является довольно узким спектром
частот колебаний воздуха.
2.
Алгоритмическая теория информации
Сравнительно
недавние открытия объединили
области компьютерной науки и
теории информации в новую науку,
алгоритмическую теорию информации.
Эта область наиболее хорошо
известна по своему основному
результату, Колмогоровской
сложности, позволяющему понять
законы информации, используемой
для создания моделей систем, как
научных, так и экономических.
Возможно, по
причине новизны этой области науки
наилучшим источником информации по
ней является Интернет. Информация,
на которой основана эта статья,
взята из Интернета. Поэтому я
привожу в разделе “введение”
переведённые мною с английского
языка и обобщённые из различных
источников основные понятия
алгоритмической теории информации
и понятия, ею используемые.
А) Принцип
нескольких объяснений связан с
тем, что многие явления могут иметь
несколько взаимоисключающих
объяснений, претендующих на то,
чтобы оказаться правильными, но
имеющихся знаний недостаточно для
оправданного выбора какого-либо
одного объяснения. Например, если
автомобиль не заводится, вы не
можете точно ответить, что является
причиной этого: разрядка
аккумулятора, отсутствие топлива в
бензобаке или что-либо другое, не
открыв капот или не спросив
специалиста, но вы можете с
уверенностью утверждать, что
случилось что-то в этом роде.
Б) Принцип
предпочтения наиболее простого
объяснения. Этот принцип
наиболее хорошо известен под
названием “лезвие Оккама” (Occam’s
Razor) и предполагает выбор наиболее
простой гипотезы, как наиболее
вероятной, из всех допустимых
гипотез, которые могут оказаться
правильными. Он похож на первое
правило натуральной философии
Ньютона, утверждавшего, что
“Единственными возможными
причинами природных явлений,
достойными рассмотрения, являются
одновременно правильные и
достаточные для их объяснения.
Природа ничего не делает без
причины и любит простоту”.
В) Правило
Байеса. Английский математик
усовершенствовал принцип
нескольких объяснений. Вместо того,
чтобы принимать все гипотезы,
объясняющие факты, как
равноправные, он предложил метод
присвоения им вероятностей:
Вероятность
верности гипотезы прямо
пропорциональна произведению
предварительной вероятности
гипотезы и вероятности того, что
полученные данные были бы получены,
предполагая, что гипотеза верна.
Допустим, мы имеем
предварительное распределение
вероятности P(H) на все возможные
гипотезы. Нам необходим полный
список взаимоисключающих гипотез,
чтобы SP(H)=1, при суммировании
по всем возможным гипотезам H.
Предположим также, что для всех H
можно найти вероятность Pr(D|H), что
данные D будут получены при условии,
что H верна. Тогда можно найти
вероятность того, что данные D могут
быть получены вообще, при всех
гипотезах:
Pr(D)= S
Pr(D|H)P(H),
при суммировании
по всем гипотезам. Из определения
условной вероятности можно
получить стандартную
математическую форму записи
правила Байеса:
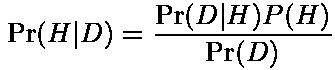
где Pr(H|D) -
вероятность верности гипотезы (при
полученных данных);
Pr(D|H) - вероятность
того, что полученные данные были бы
получены, предполагая, что гипотеза
верна;
P(H) -
предварительная вероятность
гипотезы;
Pr(D) - вероятность
того, что данные D могут быть
получены вообще.
Pr(D) в знаменателе
является нормализующим фактором,
за счёт него по всем возможным
гипотезам SPr(H|D)=1. Способ получения
предварительной вероятности P(H)
каждой гипотезы может быть каким
угодно, но вместо него удобно
использовать предварительно
полученную Pr(H|D) при поступлении
новых данных. Таким образом, можно
циклически корректировать
конечную вероятность любой
гипотезы. При этом её погрешность
будет уменьшаться при Dt ® Ґ.
Существует
простой и наглядный пример
использования правила Байеса.
Представьте, что перед вами 2
одинаковые ёмкости, наполненные
пронумерованными шариками. Вы
знаете, что в одной (1) ёмкости 10
шариков, пронумерованных от 1 до 10, а
в другой (2) – 1000, пронумерованные от
1 до 1000, но вы не знаете, в какой
именно. Из случайно выбранной
ёмкости достают случайный шарик, и
оказывается, что он №6. Его могли
достать из любой ёмкости, так как
обе ёмкости содержат такой шарик.
Но очевидно, что вероятность того,
что его достанут из (1) в 100 раз
больше, чем из (2).
Г) Машина
Тьюринга состоит из потенциально
бесконечной по длине ленты,
разделённой на квадраты,
заполненные одним из 2х символов
“1” и “0” каждый, и механизма,
считывающего символ, находящийся
на активной позиции, и, в
зависимости от его значения,
выполняет действие, предписанное
программой, которое может быть
одним из трёх: “передвинуть ленту
на одну позицию вправо”,
“передвинуть ленту на одну позицию
влево” и “переписать символ на
активной позиции на обратный (ноль
единицей или единицу нулём)”, а
затем переходит на следующую
инструкцию. В программе машины
Тьюринга возможны циклы, так как
любую инструкцию можно сделать
следующей для нескольких.
Понятие машины
Тьюринга часто используется вместо
более абстрактного понятия
универсальной вычислительной
модели. Существуют другие такие
модели, но они все эквивалентны в
соответствии с теоремой Чёрча (хотя
сильно отличаются с первого
взгляда). Другими основными
моделями являются частично
рекурсивная функция (partial recursive
function), система Поста, Марковский
алгоритм.
Д) Колмогоровская
(или алгоритмическая) сложность.
Представьте, что вам предлагают
сделать выгодную ставку на
результаты ста бросков монеты: если
выпадает лицевая сторона, вы
получаете $2, а если обратная, вы
платите $1 за каждый бросок. В
результате выпадает 100 лицевых
сторон, и вы лишаетесь $200. Вы
утверждаете, что ваш противник вас
обманывает, а он, ссылаясь на
классическую теорию вероятности,
объясняет, что любая
последовательность результатов
ста бросков монеты имеет
одинаковую вероятность, 1/2100.
В середине 60х
годов 3 учёных – Рей Соломонофф,
Андрей Колмогоров и Грегори Чаитин
независимо друг от друга изобрели
понятие, сейчас известное под
названием Колмогоровской
сложности. В поисках точного и
универсального определения
закономерности и хаотичности они
пришли к выводу, что оптимальной
единицей измерения сложности любой
информации является длина наиболее
короткой программы, способной
генерировать данную информацию.
Этот вывод является комбинацией
принципа предпочтения наиболее
простого объяснения и
представлений об алгоритмах. Как
правило, в качестве единицы
измерения Колмогоровской
сложности данной двоичной
(бинарной) строки используют длину
наиболее короткой программы машины
Тьюринга, эффективно (с
максимальной плотностью)
закодированной в двоичном
представлении. C(x)=l(p), где C – К.
сложность, x – бинарная строка, l –
функция взятия длины, p – наиболее
короткая программа машины
Тьюринга, генерирующая x, в
эффективном двоичном
представлении. Колмогоровскую
сложность можно охарактеризовать
как закономерность.
Рассмотрим
следующие последовательности:
(1) 00000000000000000000000000,
(2) 01000110110000010100111001,
(3) 10010011011000111011010000.
Последовательность
(1), очевидно, очень закономерна, так
как её можно описать как “26 нулей”.
Закономерность последовательности
(2) не настолько очевидна, но, тем не
менее, она на самом деле
закономерна, так как является
перечислением двоичных
последовательностей в
нестандартном бинарном
представлении натуральных чисел,
преимущественно используемом в
АТИ:
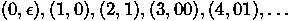
где e - пустота. Она может
быть сгенерирована циклом с
инкрементируемой переменной, при
каждой итерации выводимой в
описанном представлении. Строка (3)
пройдёт криптографические тесты на
(псевдо-)случайность.
Необходимо
заметить, что доказан тот факт, что
Колмогоровская сложность любого
данного объекта практически
независима от используемой
универсальной вычислительной
модели или языка программирования.
В идеальном случае она одинакова во
всех таких моделях с точностью до
некоторой положительной константы,
индивидуальной для каждой модели, Cn(x)=K(x)+Tn, где x – любой объект, n
– любая данная модель, Cn(x) – вычислительная
сложность объекта в данной системе,
K(x) – “чистая” Колмогоровская
сложность x, Tn – константа,
индивидуальная для каждой модели и
не зависящая от конкретного
объекта. На самом деле в
используемых языках
программирования высокого уровня
возможны отклонения T от
постоянного значения для различных
x, так как сам язык иногда содержит
подпрограммы, укорачивающие
описания отдельных объектов.
Е) Универсальное
распределение вероятности (или
просто универсальное
распределение). Существует
универсальный способ присвоения
вероятностей двоичным строкам (а,
следовательно, и любым другим
объектам, так как любой объект
может быть представлен в виде такой
строки), найденный Соломоноффым.
Пусть K(x) – Колмогоровская
сложность строки x. Тогда её
вероятность
P(x)=2 -K(x).
Необходимо
уточнить, что во множестве всех
программ, использующихся в
нахождении K, не должно быть
программ, приставкой которых
являются другие программы, так как
доказано, что в противном случае
сумма вероятностей всех строк не
будет равна 1. Это проще всего
обеспечить, выделив специальный
символ обозначения конца программы
и поставив его в конце каждой
программы.
Ж) Теорема
Тьюринга: Всё в реальности, что
может быть выполнено посредством
алгоритма, может быть выполнено
машиной Тьюринга. Не существует
ничего способного выполнить
операции над информацией,
невыполнимые машиной Тьюринга.
З) Теорема Чёрча:
Все созданные универсальные
вычислительные модели и
универсальные вычислительные
модели, которые будут созданы в
будущем, эквивалентны. Модель с
большими возможностями не будет
найдена никогда.
И) Следствия теорем
Тьюринга и Чёрча. Из данных
теорем следует, что
алгоритмическая теория информации
универсальна вообще. Все без
исключения процессы, происходящие
в природе, потенциально (в
идеальном смысле) моделируемы
любой универсальной
вычислительной моделью, частными
случаями которых являются
компьютеры общего назначения на
кремниевых чипах,
разрабатывающийся квантовый
компьютер, ДНК-процессоры и, скорее
всего, мозг человека. Полнота
моделирования ограниченна
скоростью процессора, объёмом
памяти и количеством информации о
системе, которую необходимо
моделировать. Важно то, что
структура объектов и алгоритмов не
зависит от их представления,
которое представляет собой “форму
записи”. Это означает, что реальная
дискретная физическая система и её
информационная цифровая модель
вполне могут быть абсолютно
эквивалентны.
К) Теория
рекурсивных функций основана на
том, что любой алгоритм можно
представить в виде функции,
рекурсивно использующей саму себя,
а также использующей один или
несколько раз другие рекурсивные
функции. Рекурсивные функции
работают с натуральными числами,
которые могут быть использованы
для представления любой
информации. Фундаментальными
являются понятие нуля, 0, функции
следующего s(x) и предыдущего pred(x)
чисел для данного числа x,
“техническая” функция проекции pn(f(x1,
x2, …,xm))=xn, служащая для взятия
значения аргумента функции.
Используются также условные
выражения. Все арифметические
операции над натуральными числами
могут быть определены как
рекурсивные функции. Данная теория
лежит в основе языка
программирования LISP.
Л) Чёрный ящик –
объект, о внутреннем устройстве
которого вы не имеете никакого
представления.
II.
Цель работы
- Найти
эволюционную цель интеллекта
- Объяснить
понятие обучения
- Обосновать
предсказуемость в реальных и
мета системах
- Объяснить
причины эффективности
математики по отношению к
реальным системам
- Найти
оптимальную универсальную
вычислительную модель
- Найти
фундаментальные ограничения
существующего программного
обеспечения
- Разработать
технологию универсального
вычислительного обучения
- Найти
возможности реализации
технологии универсального
вычислительного обучения
- Проблема
предсказания состояний в
физических системах
квантового уровня и принцип
Неопределённости
- Универсальное
вычислительное обучение и
теория хаоса
- Универсальное
вычислительное обучение и
теория игр, применение в
экономическом поведении
III.
Решение
- Эволюционный
отбор является стихийным
процессом, при котором
выживают особи или системы,
наиболее способные
приспособиться к процессам
постоянного изменения
окружающей среды. Это
относится как к биологическому
отбору, так и к экономическому,
имеющему место в условиях
рыночной экономики. Очевидно,
что для приспособления
к процессам изменения
окружающей среды необходимо
уметь предсказывать её
изменения. Поэтому я считаю,
что основной эволюционной
целью интеллекта является
предсказание последующих
состояний окружающей среды.
Причём вероятность выживания
носителя интеллекта прямо
пропорциональна качеству
этого предсказания, которое
зависит от количества (полноты)
и качества (достоверности)
имеющейся информации об
окружающей среде и
интеллектуального потенциала
носителя. Поэтому способность
отличить закономерность от
случайности лежит в основе
нашей интуиции. Существует
эволюционно-кибернетическая
теория метасистемного
преобразования, которая
утверждает, что информация,
имеющая место в человеческом
обществе, подвергается
эволюционному отбору в
процессе её обмена и проверки в нём.
Выживают только эволюционно
наиболее устойчивые в данной
среде концепции и методы.
- Обучение можно
свести к предсказанию
распределения вероятности на
все или некоторые (наиболее
вероятные) выходы из чёрного
ящика при наличии
определённого количества
примеров пар вход-выход
(состояний) для этого чёрного
ящика. Чёрным ящиком вполне
можно считать окружающую
среду.
- Почему можно
делать какие-либо предсказания
или обобщённые утверждения о
реальных системах? Причина в
том, что реальность частично
упорядочена (алгоритмически
целостна). Не будь она таковой,
мир был бы полным хаосом, и в
принципе не существовал бы.
Поэтому существует
универсальное распределение.
Поэтому вероятность
существования любой системы
обратно пропорциональна длине
наименьшей программы,
способной представить эту
систему. Это следует из теоремы
Чёрча и того, что реальные
системы стремятся к тому, чтобы
быть алгоритмически
целостными. Говоря кратко,
частичная предсказуемость
реальных систем обусловлена
тем, что мир стремится к тому,
чтобы не быть абсолютным
хаосом.
- Физика
является наукой, наиболее
тесно связанной с реальными
системами. Физические задачи
связаны с поиском недостающих
параметров системы по заданным
параметрам, что можно
рассматривать как
предсказание параметров
алгоритмически целостной
системы. В процессе решения
используется преобразование,
чаще всего упрощение
математических выражений и в
ответе, как правило, стоит
математическая формула, а
иногда система уравнений с
использованием условных
выражений. Какое это имеет
отношение к АТИ? Дело в том, что
математика является одной из
универсальных вычислительных
моделей. Её формы записи не
всегда предельно эффективны,
но она является наиболее
удобной для использования
человеком. Наиболее близкой к
математике является теория
рекурсивной функции, в которой
также существуют операции
умножения, деления, факториала
и может быть определена любая
другая математическая
операция. Все математические
операции могут быть определены
рекурсивно: умножение через
сложение, возведение в степень
– через умножение и т.д.
Например, на низком уровне
4*3=4+4*2=4+4+4*1=4+4+4+4*0=4+4+4=12.
Математика может быть заменена
любой другой универсальной
вычислительной моделью.
- В настоящее
время в исследованиях в
области АТИ основной
используемой универсальной
вычислительной моделью
является машина Тьюринга.
Считаю, что эта модель не
является оптимальной,
поскольку не является
предельно простой. Предлагаю
использовать другую модель,
которую можно рассматривать
как упрощённый вариант
рекурсивной функции. Я считаю,
что вместо двоичных
последовательностей удобнее
использовать соответствующие
им натуральные числа. Это
устранит возможную проблему с
тем, что модели различных
систем могут иметь одинаковую
сложность в двоичной системе
записи, но в реальном
представлении их сложность
будет отличаться. Примечание:
это может показаться не
очевидным, но для значительной
доли натуральных чисел
существует алгоритм, способный
их выводить, величина
натурального числа,
соответствующего которому
меньше (а для некоторых намного
меньше) величины самого числа.
Причём это далеко не полностью
определяется величиной числа.
Например, рекурсивный алгоритм
вычисления значения выражения
(((22)2)2)2 очень короток, но
для подавляющего большинства
чисел порядка его значения 1019728 не существует
даже алгоритма вычисления
меньшей длины, чем сами эти
числа.
- Почти всё
используемое сейчас
программное обеспечение
ориентировано исключительно
на решение абсолютно
конкретных задач. Людьми
написаны алгоритмы для решения
огромного множества
всевозможных задач, касающихся
различных конкретных систем.
Весь системный анализ при этом
выполняется программистами,
так как пока не реализованы
эффективные алгоритмические
методы системного анализа, что
является одной из основных
целей современной
алгоритмической теории
информации. Компьютеру
остаётся лишь выполнять
программу. Он не в состоянии
обучаться и выполнять
индуктивную экстраполяцию.
Существующее сейчас
“разумное” программное
обеспечение, способное
выполнять распознавание
образов или какую-либо
экстраполяцию, нейронные сети
и генетические алгоритмы,
найденные в основном путём
проб и ошибок, имеют
существенные ограничения и
недостатки.
- Представьте
себе чёрный ящик, имеющий вход
и выход. Вы знаете несколько
пар вида вход-выход: 1-1, 2-4, 3-9, 4-16.
Как вы думаете, что, скорее
всего, будет на выходе для
некоторого числа, например 7, на
входе? Решение задач, полностью
подобных этой, является
основной целью искусственного
интеллекта. Назовём пару вида
вход-выход состоянием, а вход и
выход компонентами состояния. Вообще, у
состояния может быть и более
двух компонентов, но это для
нас не очень существенно.
Назовём множество
потенциально возможных
состояний системой. Все задачи
по предсказанию можно свести к
виду: "Известно, что система S
имеет множество состояний M (состояния даны
полностью), но может также
иметь и другие состояния.
Известен один из компонентов
некоторого состояния Sn (состояние
изначально не дано, поэтому
больше ничего о нём не
известно). Найти другой (другие)
компонент(ы) состояния Sn". Для решения
подобной задачи необходимо
найти оптимальную систему в
бесконечном множестве систем,
ограниченном заданными
условиями. Но поскольку ничего
неизвестно о существовании и
виде состояний, кроме тех,
которые даны, и того, которое
необходимо найти, достаточно
рассматривать
системы, имеющие только такие
состояния. Оптимальной будет
система, имеющая наибольшую
вероятность в соответствии с
универсальным распределением.
Таковой будет система (в виде
множества чисел), имеющая
минимальную Колмогоровскую
сложность, то есть, с наиболее
коротким алгоритмическим
описанием. Поэтому необходимо
найти такое состояние Sn, при котором длина
алгоритмического описания
всей системы будет
минимальной. Алгоритмическое
описание системы можно
рассматривать как алгоритм,
способный генерировать каждое
заданное состояние и любое из
состояний, отвечающих
условиям, предъявленных к Sn. Таким образом,
необходимо найти алгоритм в
форме, кратко описанной в
пункте 4, который будет
наименьшей длины и который
будет отвечать указанным
требованиям. При этом Sn примет некоторое
конкретное значение, которое и
будет решением. Конечно, чтобы
найти такой алгоритм,
необходимо рассмотреть
огромное количество вариантов,
но сравнительно несложные
задачи должны, без сомнения,
быть под силу и сегодняшним
компьютерам с тактовой
частотой даже в несколько
сотен мегагерц. Любую систему
или задачу можно условно
представить или рассматривать
в форме указанной модели и,
если данных достаточно, можно
использовать описанный способ
для получения предсказаний или
решений, имеющих
наибольшую вероятность
оказаться правильными, в такой
же условной форме
представления. По следствию из
теоремы Чёрча, форма
представления любой системы не
меняет её структуры и,
следовательно, свойств, при
условии, что при
преобразовании в эту форму не
происходит достаточно большая
потеря информации. Поскольку
все задачи можно представить в
таком виде, область применения
такой технологии потенциально
не ограниченна.
- Несмотря на
полное отсутствие реализаций
подобных технологий на данный
момент, я считаю, что описанная
технология реализуема, хотя её
возможности на персональных
компьютерах были бы довольно
ограничены из-за
недостаточного
быстродействия. В качестве
аргумента реализуемости можно
привести эффективность работы
современных
программ-архиваторов (RAR, JAR, GZIP
и др.), которые выполняют сжатие
информации именно за счёт её
алгоритмической целостности,
используя алгоритмы, подобные
динамическому Марковскому
кодированию DMC и PPM,
использующие предсказуемость
данных для удаления излишка
информации, а также
математического программного
обеспечения (Derive 4.0, Maple 5.0),
способного за несколько минут
выполнять разложение на
множители чисел порядка 1050, что для
определённой группы чисел
является хорошим алгоритмом
поиска их наиболее короткого
алгоритмического описания.
Наибольшим ограничением
является то, что поиск наиболее
короткого описания требует
очень больших вычислительных
ресурсов, но это ограничение
должно быть преодолено при
создании квантового
компьютера.
- Принцип
неопределённости Гейзенберга
является одним из
фундаментальных в квантовой
физике. Он утверждает, что хотя
не существует пределов
точности, с которой могут быть
определены либо импульс, либо
положение элементарной
частицы, существует
принципиальный предел
точности определенности обеих
величин в один и тот же момент
времени. Из этого следует,
например, что даже при
абсолютном нуле частицы должны
находиться в непрерывном
хаотичном движении (иначе он
будет нарушен) и,
следовательно, должна
существовать энергия вакуума.
Нас же интересует другое
связанное с этим следствие, а
именно, что информации о
состоянии реальной системы
квантового уровня в данный
момент времени может быть
недостаточно для однозначного
предсказания её состояния в
любой последующий момент.
Причём качество наилучшего
предсказания падает с
увеличением временного
промежутка. Это означает, что
существуют фундаментальные
ограничения предсказания
будущего в физической
реальности. Тем не менее,
существуют системы даже
квантового уровня, остающиеся
в рамках полной
предсказуемости с течением
времени, что лежит в основе
проекта создания квантового
компьютера. Описанное
следствие принципа
неопределённости не играют
роли в предсказании состояний
реальных систем высокого
уровня, но могут иметь значение
при применении технологии
вычислительного
прогнозирования в
теоретической физике.
- Теория хаоса
изучает предсказание
состояний систем, имеющих
высокую алгоритмическую
сложность в условиях наличия
неполной информации о них. Даже
в таких системах описанная
технология должна давать
предсказание настолько
эффективное, насколько это
возможно. Тем не менее,
прогнозирование в хаотичных
системах должно требовать ещё
больших вычислительных
ресурсов и времени.
- Экономическое
поведение неразрывно связано с
теорией игр. Основной целью
теории игр является
прогнозирование результата
взаимодействия сторон, имеющих
определённые интересы.
Основной целью экономического
поведения является
прогнозирование ситуации на
рынке и действий противников,
качество которого играет
первостепенную роль для любой
организации, каким-либо
образом связанной с рынком в
условиях рыночной экономики.
Поэтому основные цели теории
игр и экономического поведения
являются частными случаями
цели универсального
вычислительного обучения.
Экономические системы
формально ничем не отличаются
от любых других хаотичных
систем, и универсальное
вычислительное обучение может
стать новым мощным средством
многоцелевого экономического
прогнозирования.
IV.
Выводы
- Основной
эволюционной целью интеллекта
является предсказание
последующих состояний
окружающей среды.
- Обучение можно
свести к предсказанию
распределения вероятности на
все или некоторые (наиболее
вероятные) выходы из чёрного
ящика при наличии
определённого количества
примеров пар вход-выход
(состояний) для этого чёрного
ящика.
- Частичная
предсказуемость реальных
систем обусловлена тем, что мир
стремится к тому, чтобы не быть
абсолютным хаосом.
- Математика
является одной из
универсальных вычислительных
моделей.
- Вместо
двоичных последовательностей
удобнее использовать
соответствующие им
натуральные числа, что
устранит возможную проблему с
тем, что модели различных
систем могут иметь одинаковую
сложность в двоичной системе
записи, но в реальном
представлении их сложность
будет отличаться.
- Для
значительной доли натуральных
чисел существует алгоритм,
способный их выводить,
величина натурального числа,
соответствующего которому
меньше (а для некоторых намного
меньше) величины самих этих
чисел.
- Почти всё
используемое сейчас
программное обеспечение
ориентировано исключительно
на решение абсолютно
конкретных задач. Весь
системный анализ при этом
выполняется программистами,
так как пока не реализованы
эффективные алгоритмические
методы системного анализа.
- Технологии
нейронных сетей и генетических
алгоритмов найдены в основном
путём проб и ошибок и поэтому
имеют существенные
ограничения и недостатки.
- Область
применения технологии
универсального
вычислительного обучения
потенциально не ограниченна.
- Поиск наиболее
короткого алгоритмического
описания требует очень больших
вычислительных ресурсов, но
это ограничение должно быть
преодолено при создании
квантового компьютера.
- Существуют
фундаментальные ограничения
предсказания будущего в
физической реальности.
- Прогнозирование
в хаотичных системах требует
наибольших вычислительных
ресурсов и времени.
- Основные цели
теории игр и экономического
поведения являются частными
случаями цели универсального
вычислительного обучения.
V.
Литература
- M. Li and P.M.B. Vitanyi, An Introduction to Kolmogorov
Complexity and Its Applications, 2nd edition,
Springer-Verlag, 1997.
- M. Li and P.M.B. Vitanyi, Worst case complexity is equal
to average case under the universal distribution,
Information Processing Letters, 1992
- A.M. Turing, On computable numbers with an application to
the Entscheidungsproblem, Proc. London Math. Soc., Ser.
2, 42(1936); Correction, Ibid, 43(1937)
- W. Kirchherr, M. Li and
P.M.B. Vitanyi, The Miraculous Universal Distribution,
опубликована на Internet
- M. Li and P.M.B. Vitanyi,
Theories of Learning, опубликована на
Internet
- M. Li and P.M.B. Vitanyi, On
Prediction by Data Compression, опубликована
на Internet
- M. Li and P.M.B. Vitanyi,
Computational Machine Learning in Theory and Praxis,
опубликована на Internet
- J.J. Rissanen, Modeling by the shortest data description,
Automatica-J.IFAC 14, 1978
- P.M.B. Vitanyi, Ideal MDL
and Its Relation To Bayesianism, опубликована
на Internet
- M. Li and P.M.B. Vitanyi,
Minimum Description Length Induction, Bayesianism, and
Kolmogorov Complexity, July 8, 1998,
опубликована на Internet
- P.M.B. Vitanyi, Physics and
the New Computation, опубликована на
Internet
- А. Шафранюк,
работа по теме “Перспективные
информационные технологии” о
применении генетических
алгоритмов и ДНК-процессоров в
физике, Малая Академия Наук, 1997
- Nick Szabo, Introduction to
Algorithmic Information Theory, 1996,
опубликована на Internet
- David Matuszek, Church’s
Thesis, 1996, опубликована на Internet